Не спешите думать, что заголовок представляет собой набор несвязанных фраз, сейчас я постараюсь всё объяснить.
Итак, всё началось с того, что передо мной возникла следующая задача: у меня есть некое устройство с веб-сервером (самодельная железка), которое я подключаю к домашней сети в качестве DHCP-клиента. Вопрос — как найти подключенное устройство (узнать полученный им IP-адрес), пользуясь только web-браузером, запущенным на другом устройстве из в этой же сети (скажем, на домашнем ПК, планшете или смартфоне).
При этом вариант, когда я просто захожу через браузер в веб-интерфейс роутера и смотрю кому какие адреса он выдал — не подходит, поскольку если я завтра поменяю роутер, то у нового может оказаться совершенно другой веб-интерфейс, а решение должно работать с любым роутером. Другими словами, нужно средствами браузера сделать сканер домашней сети.
Сразу скажу, что если кто-то подскажет лучшее решение — с удовольствием рассмотрю и почитаю, я же рассуждал следующим образом: можем ли мы посылать с открытой web-страницы какие-либо запросы? Да, можно посылать асинхронные http-запросы используя технологию AJAX. Отлично, — сюда и будем копать.
Обычно AJAX используют для того, чтобы получать данные с того же сервера, с которого была загружена сама страница. Например, чтобы что-то догрузить или в реальном времени перестраивать страницу в соответствии с меняющимися данными (такое использование AJAX я уже ранее описывал в статье про веб-АСУТП аквариума — обязательно почитайте). Ок, но как обстоят дела с кроссдоменными запросами? Для этого придётся копнуть поглубже.
Технология AJAX построена вокруг использования встроенного объекта XMLHttpRequest (иногда его сокращённо называют XHR), стандарт на который можно скачать на сайте whatwg.org (там всегда актуальная свежая версия). Этот стандарт с одной стороны не запрещает нам отправлять запросы по любому адресу в сети, но с другой стороны следует так называемой «политике одного источника» (same-origin-policy).
Следование «политике одного источника» означает, что вы конечно можете отправить AJAX-запрос куда угодно, но если адрес запроса отличается от адреса, с которого открыта страничка (определяется по значению поля Origin в запросе), то браузер вам этот ответ просто не покажет. Прямо как в мультике про Простоквашино, — «Вам посылка, только я вам её не отдам, потому что у вас докУментов нет». При этом убедиться, что браузер посылку, тьфу, то есть ответ, на самом деле получает можно, например, с помощью встроенного в firefox от mozilla отладчика (F12).
Вот так в мозилле выглядит результат работы небольшого тестового скриптика на javascript, встроенного в тестовую веб-страницу, который отправляет запросы на пачку адресов заданного сегмента (к тестовому же php-скрипту) и формирует на страничке таблицу с кодами ответов для каждого выполненного запроса:
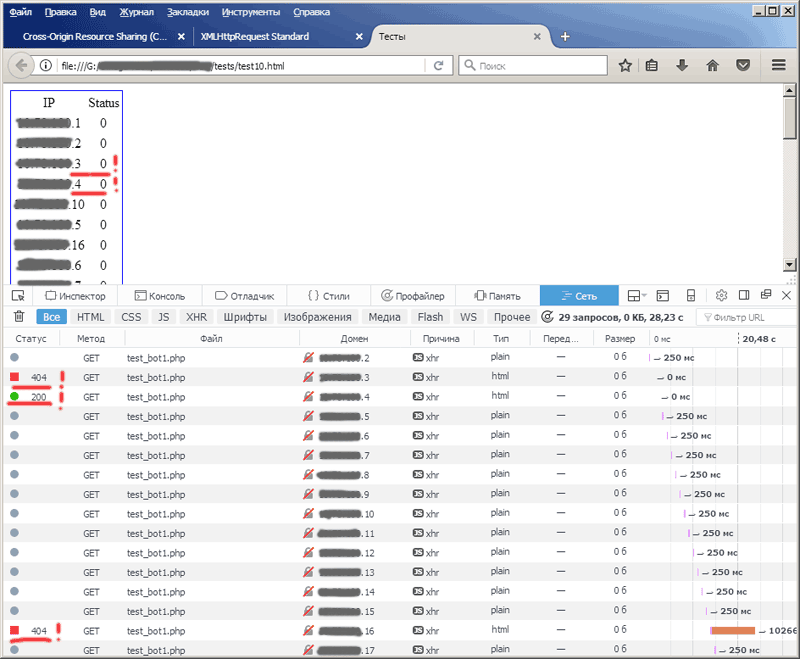
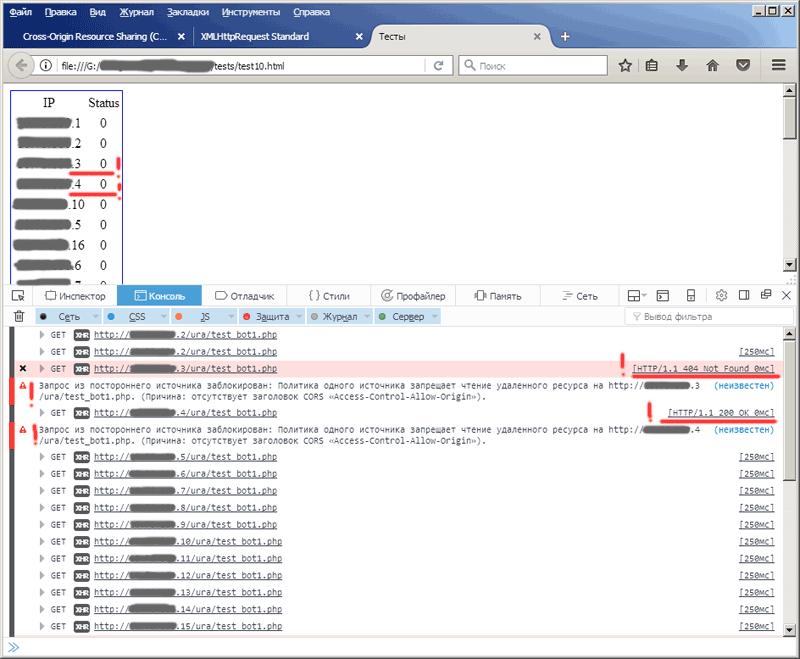
Как видите, с адресов 3 и 4 приходят ответы с кодами 404 (Not Found) и 200 (OK), но браузер нашему скрипту эти ответы не отдаёт, — в таблице одни нули. То есть на 4-м адресе у нас есть сервер, на котором расположен наш тестовый php-скрипт, браузер это видит, получает от этого php-скрипта ответ, но нам его не показывает. На второй картинке браузер сообщает нам причину такого хамского поведения: «… Политика одного источника запрещает чтение удалённого ресурса…»
Хм, а что это у нас такое в скобках: «отсутствует заголовок CORS «Access Control-Allow-Origin». Ну-ка, ну-ка, покопаемся в сети. Да это же подсказка, оставленная нам разработчиками мозиллы.
CORS (Cross-Origin Resource Sharing) — это стандарт, описывающий механизм реализации кросс-доменных http-запросов. В оригинале можно почитать вот здесь. Читать обязательно. Если в кратце, то суть в том, что если сервер, к которому обращаются с кроссдоменным запросом, выдаст нам разрешение, то браузер закроет глаза на свою политику одного источника и всё-таки отдаст скрипту полученный ответ.
То есть политика одного источника — не догма, а всего лишь опция по умолчанию, которую мы при желании можем немного расширить, если договоримся с сервером о специальном разрешении. Но мы то с сервером договоримся, мы же своё собственное устройство в сети ищем, соответственно и настраивать его можем как хотим, осталось только выяснить как выдать разрешение.
Разрешение выдаётся с помощью специального дополнительного заголовка в ответе: Access-Control-Allow-Origin. В этом заголовке сервер указывает каким источникам (поле Origin в заголовках запроса) браузеру разрешено отдавать полученные ответы. Можно выдать разрешение отдавать ответы web-страницам запущенным не из сети, а с локального компа. У таких страниц в поле Origin записан null и, соответственно, для них разрешение от сервера должно выглядеть так: Access-Control-Allow-Origin: null . Можно вообще положить на политику одного источника болт, прописав в ответе сервера Access-Control-Allow-Origin: * .
Давайте повторим наш предыдущий эксперимент с тестовой страничкой, только теперь в php-скрипте, к которому мы обращаемся, пропишем в ответе заголовок Access-Control-Allow-Origin: null . Результаты можно видеть на картинках ниже:
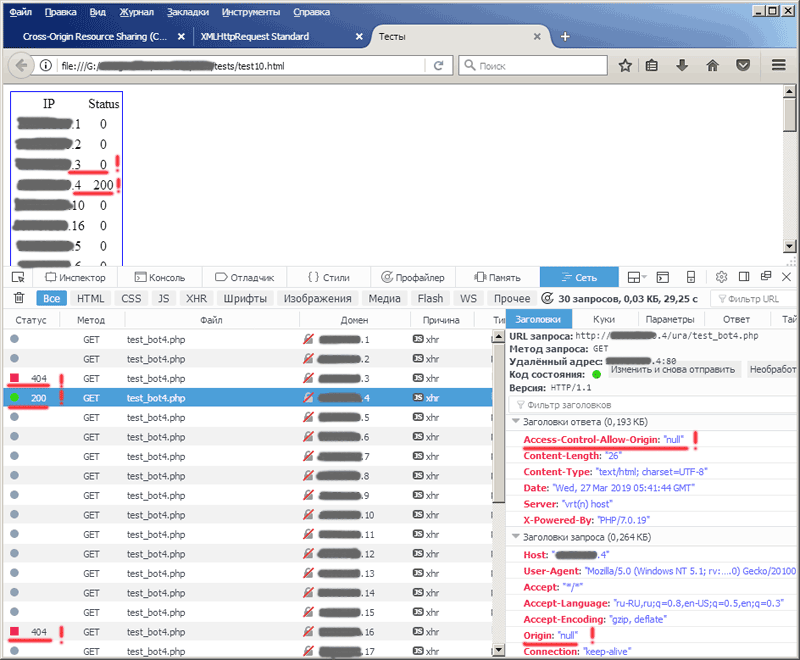
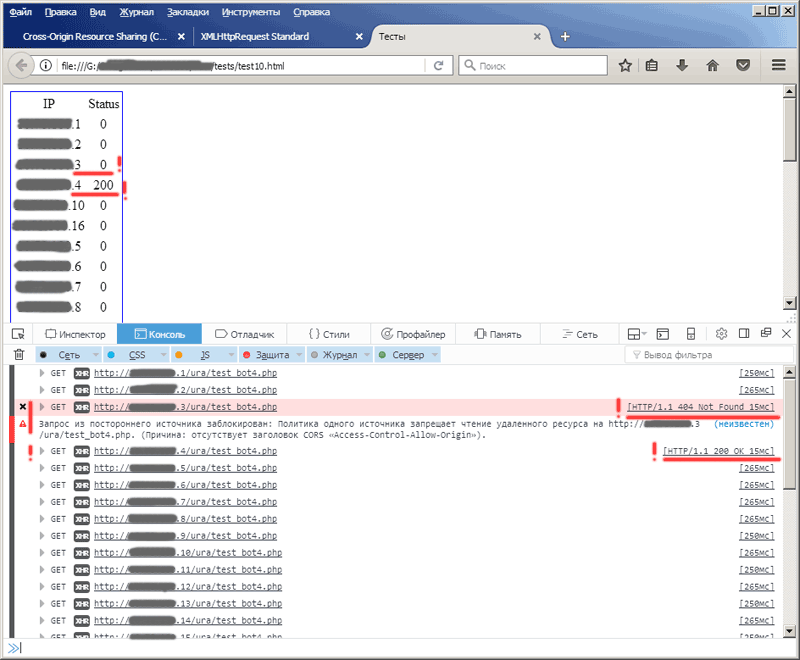
Как видите, теперь ответ с адреса 3 (статус 404) для нас по-прежнему заблокирован, а вот ответ с адреса 4 браузер нам отдаёт (этот адрес появился в таблице и мы видим, что для него был получен статус 200).
Итак, если мы имеем возможность настроить заголовки ответа web-сервера, то можно сделать сканер сети, который будет обнаруживать в ней наши устройства (имеющие настроенные нами веб-серверы). Ниже приведены исходники тестового php-скрипта (отвечающего с заданным хидером Access-Control-Allow-Origin) и странички со встроенным сканером сети на javascript.
<?php /* выключаем протоколирование ошибок */ error_reporting(0); // добавляем хидер, иначе браузер не покажет нам ответ (политика одного источника) header('Access-Control-Allow-Origin: null'); echo 'Test!'; ?> |
<!DOCTYPE html>
<html xmlns='http://www.w3.org/1999/xhtml'>
<head>
<title>Тесты</title>
<meta charset="utf-8" />
<script type='text/javascript'>
var i = 0; // start address = i+1
var url_numbers = 255; // end address = url_numbers
var test_time = 1000; // time to next try
var rs_flag = 0; // request started flag
var timer; // timer pointer
request_domen = 'http://192.168.1.';
request_path = '/ura/test_bot4.php';
request_port = 80;
function handle_error(){return -1;}
if (typeof getURL == 'undefined')
{ getURL = function(url, callback, i_gurl) // url, user_calback_pointer
{ if (!url) throw 'No URL for getURL';
try
{ if (typeof callback.operationComplete == 'function')
{ callback = callback.operationComplete;
}
}
catch (e) {}
if (typeof callback != 'function')
{ throw 'No callback function for getURL';
}
var http_request = null;
if (typeof XMLHttpRequest != 'undefined')
{ http_request = new XMLHttpRequest();
}
else if (typeof ActiveXObject != 'undefined')
{ try
{ http_request = new ActiveXObject('Msxml2.XMLHTTP');
}
catch (e)
{ try
{ http_request = new ActiveXObject('Microsoft.XMLHTTP');
}
catch (e) {}
}
}
if (!http_request)
{ throw 'Both getURL and XMLHttpRequest are undefined';
}
http_request.number = i_gurl; // создаём пару новых атрибутов для http_request
if(i_gurl<10) // и запоминаем в них кое-что
{ http_request.address = url.substring(7,18);
}
else if(i_gurl<100)
{ http_request.address = url.substring(7,19);
}
else
{ http_request.address = url.substring(7,20);
}
http_request.onreadystatechange = function()
{ if (http_request.readyState == 4)
{ rs_flag = 0; // сбрасываем флаг, что запрос выполняется
callback(
{ success : true,
content : http_request.responseText,
contentType : http_request.getResponseHeader("Content-Type"),
status : http_request.status,
number : http_request.number,
address : http_request.address
}
);
}
}
http_request.open('GET', url, true);
http_request.send(null); // отправляем запрос
end_flag = 1; // ставим флаг, что выполняется очередной запрос
}
}
function sendTop(i_sendtop)
{ if (request_url)
{ getURL(request_url, plot_data, i_sendtop);
}
else
{ handle_error();
}
}
function plot_data(obj)
{ if (!obj.success) return handle_error(); // getURL failed to get data
//if (!obj.content) return handle_error(); // getURL get empty data, IE problem
var table = document.getElementById('results'); // ищем нашу таблицу
tr = table.appendChild(document.createElement('tr')); // добавляем строку
td = tr.appendChild(document.createElement('td')); // добавляем ячейку
td.innerHTML = obj.address; // пишем в неё url
td = tr.appendChild(document.createElement('td')); // добавляем ячейку
td.innerHTML = obj.status; // добавляем в неё статус
}
function tests()
{ //alert("Test! i=" + i);
if((rs_flag == 0)&(i < url_numbers))
{ i++; // увеличиваем i
// формируем url
request_url = request_domen + i.toString() + ':' + request_port.toString();
request_url += request_path;
sendTop(i); // вызываем функцию sendTop
}
if(i == url_numbers) // если опросили все адреса
{ clearInterval(timer); // выключаем таймер
}
}
function getTop()
{ timer = setInterval('tests()', test_time); // запускаем таймер для периодического
} // вызова функции тестирования
</script>
</head>
<body onLoad='getTop();'> <!-- после загрузки вызываем функцию getTop -->
<table id="results" style="border: 1px solid blue; text-align: center">
<tr><td>IP</td><td>Status</td></tr>
</table>
</body>
</html> |
Хотелось бы дополнительно сделать пару пояснений по поводу последнего скрипта (скорее для себя, а то я потом напрочь забуду что тут почему).
- Зачем мы дополнительно создаём у каждого экземпляра объекта http_request атрибуты number и address? Это из-за того, что наши запросы асинхронные и к тому моменту, когда для созданного экземпляра объекта XMLHttpRequest сработает колбэк, значения этих параметров изменятся. Единственный вариант — прибить текущие значения гвоздём к самому экземпляру объекта. При срабатывании колбэка мы будем работать с тем экземпляром объекта, для которого он был установлен и, соответственно, с теми значениями, которые мы запомнили, когда создавали объект и отправляли запрос.
- Зачем нам нужен rs_flag? Этот флаг позволяет не отправлять новый запрос до тех пор, пока не обработается старый. Запросы же асинхронные и если мы не будем дожидаться выполнения старого запроса и сразу отправлять новые, то браузер просто зависнет. Можно конечно отправлять запросы и пачками, но не слишком большими, не более 5-7 штук. Почему я так не сделал? Это было бы чуть сложнее накодить и это не было целью эксперимента (хотя предыдущий пункт с прибиванием текущих значений нужных параметров к экземпляру объекта как раз под это и задумывался, чтобы потом разобраться где чей колбэк и где чьи ответы).
На этом на сегодня всё, пока.