По работе возникла задача выгрузить по нескольким тегам данные из SCADA-системы Vijeo Citect. Выгружать нужно было мгновенные значения с интервалом в 5 секунд за достаточно большой промежуток времени (чуть меньше года). Данные у нас архивируются с интервалом в 1 секунду, так что в этом смысле всё нормально, однако выгрузка прямо из скады, в лоб, большого количества данных невозможна (за раз при заданном интервале можно выгрузить значения примерно за неделю). Соответственно, встала задача как-то облегчить процесс.
О том, что данные в Vijeo Citect хранятся в папке Data (в файлах имя_тега.000, имя_тега.001, имя_тега.002 и так далее) было известно давно, но теперь я решил разобраться с форматом этих файлов, а также написать парсер, позволяющий извлекать хранящиеся там данные вообще не заходя в скаду.
В итоге выяснилось следующее:
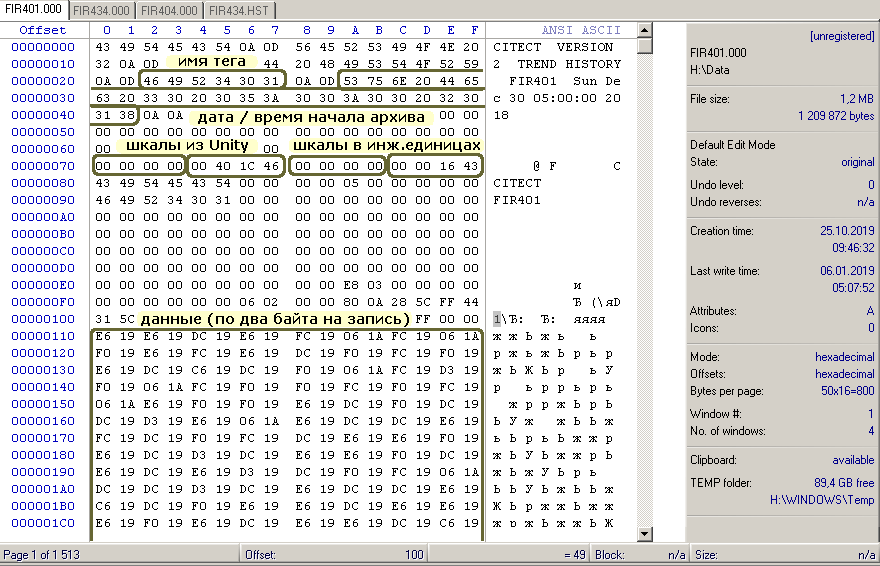
- Каждый файл начинается с заголовка, размером 0x110 байт
- По адресам 0x22-0x27 лежит имя тега
- По адресам 0x2A-0x41 лежит время начала архива (локальное время, поскольку новый файл всегда начинается в 00:00 UTC)
- По адресам 0x70..0x7F лежат шкалы в формате float (по 4 байта, little endian). 0x70-0x073 — начало шкалы АЦП из Unity, 0x74-0x77 — конец шкалы АЦП из Unity, 0x78-0x7B — начало шкалы в инженерных единицах, 0x7C-0x7F — конец шкалы в инженерных единицах.
- По адресам, начиная с 0x110 и до самого конца лежат сами архивные данные (по два байта задом-наперёд значений типа int). Чтобы перевести записанные здесь целые значения в инженерные единицы — нужно воспользоваться следующей формулой:
Result = ScaleSTART + (INT/32000)*(ScaleEND-ScaleSTART), где
ScaleSTART — начальная шкала в инженерных единицах (float по адресам 0x78-0x7B)
ScaleEND — начальная шкала в инженерных единицах (float по адресам 0x7C-0x7F)
INT — прочитанное целое значение
откуда взялись 32000 — не знаю, но это именно так (не 32768, как можно было бы предположить) - Максимальное количество данных в файле — 604800 значений (604 800*2=1 209 600 байт)
- Для указания недостоверных данных используется число -32001 (0x82 0xFF)
По результатам проведённых исследований на С++ Builder был написан парсер, позволяющий в один клик выгружать в csv из указанного файла архива мгновенные значения или формировать и выгружать часовые отчёты (интеграл за час). Последнее может быть актуально для трендов расхода (данные в архиве должны измеряться в единицах относительно часа: кг/ч, т/ч, м3/ч).

Ниже выкладываю сам парсер с исходниками (может кому пригодится).
Изначально планировалось в этом же парсере реализовать расчёт суточных интеграторов с привязкой к определённому часу, склейку всех архивов по одному тегу и некоторые другие плюшки, однако в итоге Virtual решил эти задачи, просто обработав мгновенные выгрузки парсера скриптами на баше. Естественно, сразу после этого, мне стало сильно лень доделывать все первоначальные задумки. Впрочем, это уже совсем другая история.
P.S. bash-скрипт для склейки файлов выгрузки:
#!/bin/bash
#
# скрипт для склеивания всех файлов из каталога input
# переберём все csv-шники, у каждого отрежем лишнее
# (первые 8 строк), а остальное склеим в один файл
if [ -d output ]; # проверяем наличие папки output
then # если папка существует
rm output/* # удаляем в ней все файлы
else # если папки нет
mkdir output # создаём папку output
fi
cd input # переходим в папку input
dos2unix *.csv # переделываем концы строк Windows в Unix
for i in *.csv # перебираем все файлы *.csv, которые есть в каталоге input
do
echo -n "."; # прогресс бар
tail -n +9 $i>../output/$i; # отрезаем от содержимого файла первые строки, а начиная с 9-й
# и до окнца - выводим в файл с таким же именем в папке output
done
cd .. # возвращаемся в папку со скриптом
rm all_in_one.csv # удаляем файл all_in_one.csv, если он уже был создан
cat output/*.csv> all_in_one.csv; # склеиваем всё в один файл
rm output/* # удаляем все файлы в папке output
rmdir output # и удаляем саму папку output
echo "";
counter=`cat all_in_one.csv |grep '05:00:00' |wc -l`; # считаем сколько раз в итоговом файле встречается
# строка '05:00:00' и сохраняем результат в переменную counter
let "result = counter/2" # делим пополам - получаем количество обработанных суток
echo "Количество суток в обработанных файлах: "$result;
echo "Well done!"; |
P.P.S. Ещё раз обращаю внимание, что каждый новый файл архива начинает писаться в 00:00 по UTC, а время начала, которое записано в файле — это локальное время. В выгрузке указано локальное время того места, где формировался файл архива (это нужно учитывать, если вы обрабатываете архивы, находясь не в том часовом поясе, в котором они были сформированы).